
Project
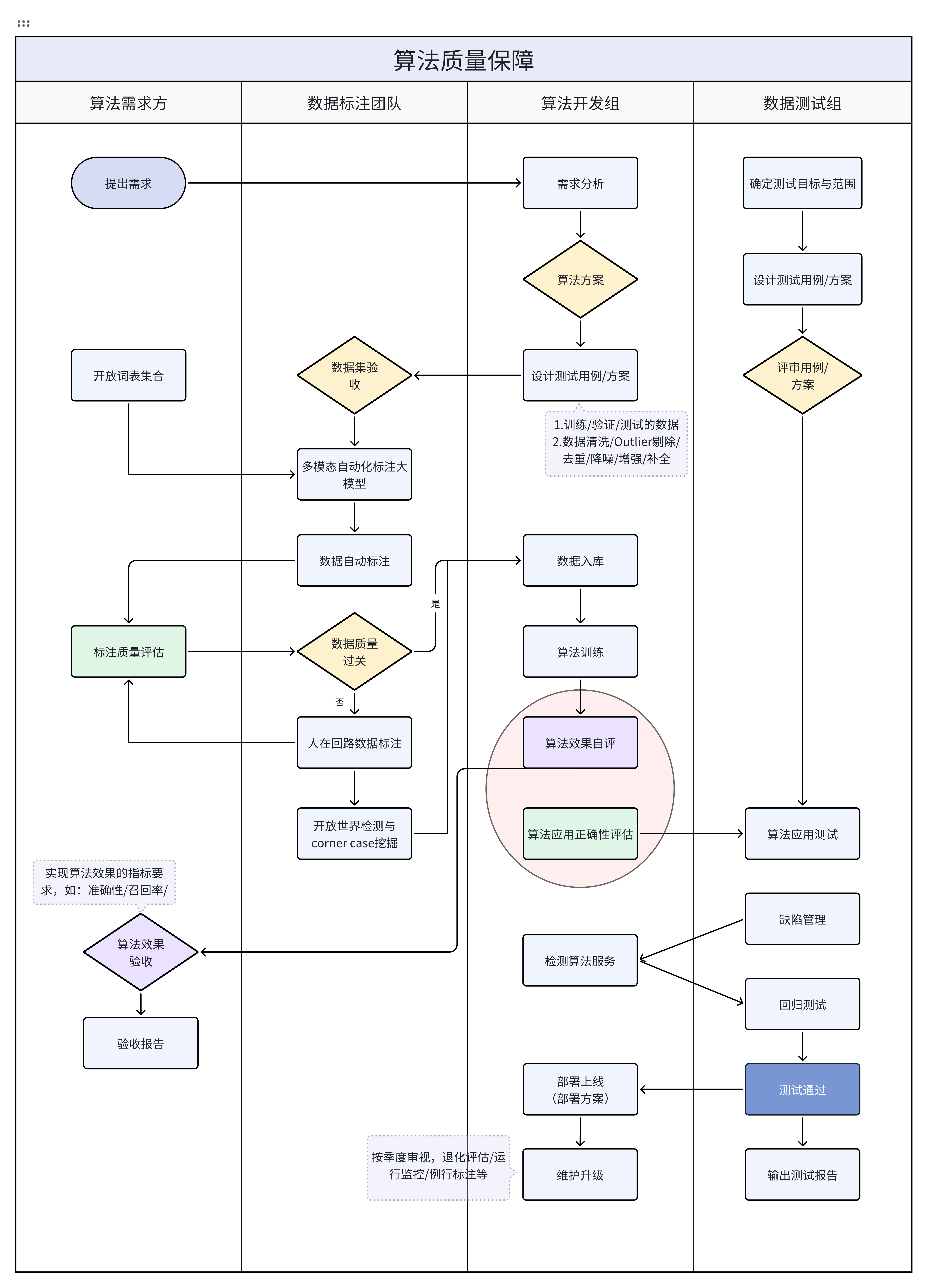
多模态开放词汇自动化标注系统
基于目标姿态与关键点的多视角视频生成系统
视频生成模型评估系统
端云协同的多模态数据飞轮系统
端侧模型优化部署方案
平台规则检索校验RAG模型
无字幕视频多语识别与字幕生成系统(个人项目)
技术产品思维之TPF&PMF
For more info
多模态开放词汇自动化标注系统
项目亮点:
- 负责多模态自动化标注系统产品化方案设计,构建基于LLM+RAG-Langchain的标注词表-法规检索系统。
- 制定开创性的开放词汇自动标注产品研发策略,并规划与搭建AI、跨模态平台产品,以SDK、API或私有化部署的方式满足业务需求,实现数据流程降本增效,同时高效对接标注上下游团队,保障项目交付。
- 可以自动生成视觉和点云数据的二维掩码、三维掩码和三维边框标注。系统集成了大语言模型(LLM)的思维链能力和视觉语言模型(VLM)的跨模态能力。
- 与传统方法相比,可以为“气球”和“碰碰车”等稀有目标提供开放词汇的三维标注。
- 可以理解具有一定逻辑思维的命令,例如“给带塑料袋的人贴标签”。系统首先通过LLM解释器和适当的提示工程来解释该请求。
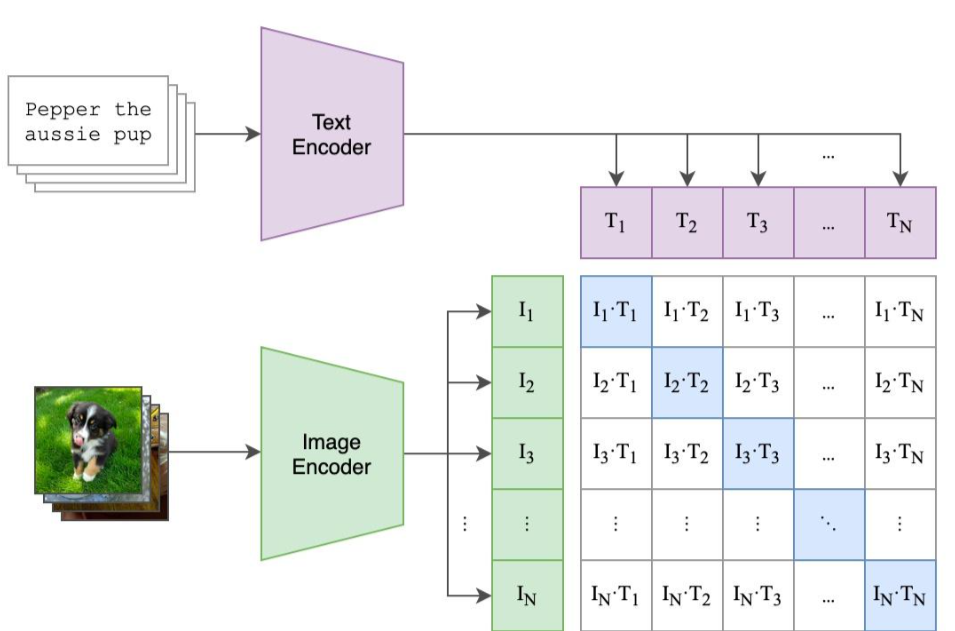
- 通过语言与视觉prompt模块(CLIP)的交互,能够解释的文本符合可提示视觉模型的推理能力。
- 生成密集的2D掩码(mask),并通过多模态空间对齐进一步计算3D掩码。且采取时空融合和校正来细化三维标签,克服二维掩码的不完全性
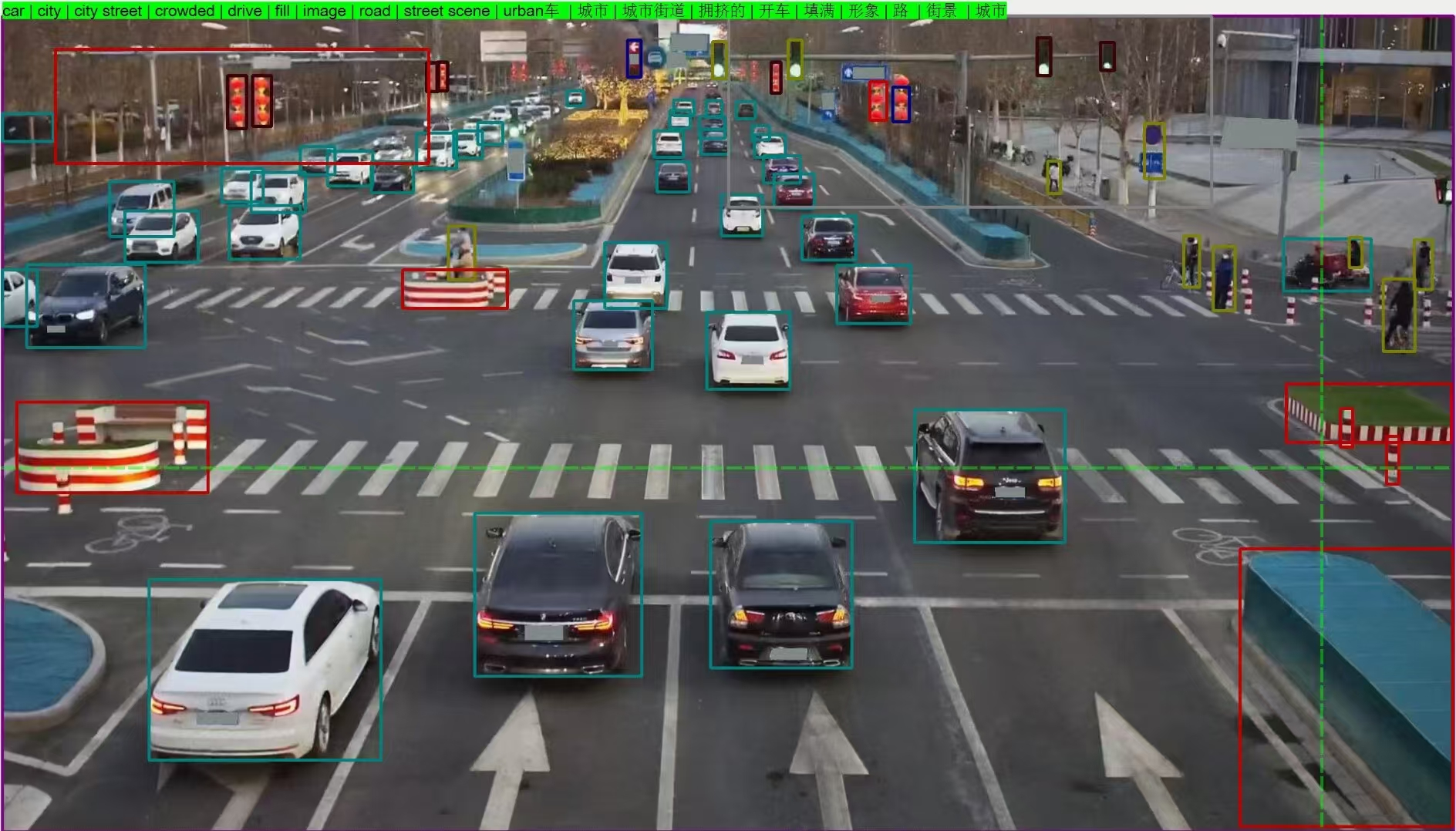
项目成果:
- 形成了标准化的开放词汇下的数据自动化标注流程,基于多模态预训练模型CLIP+Grounding DINO,实现了开放世界下多目标自动化标注,成功率高达98.6%,使检测词表由50类增加至200类(支持Prompt)。
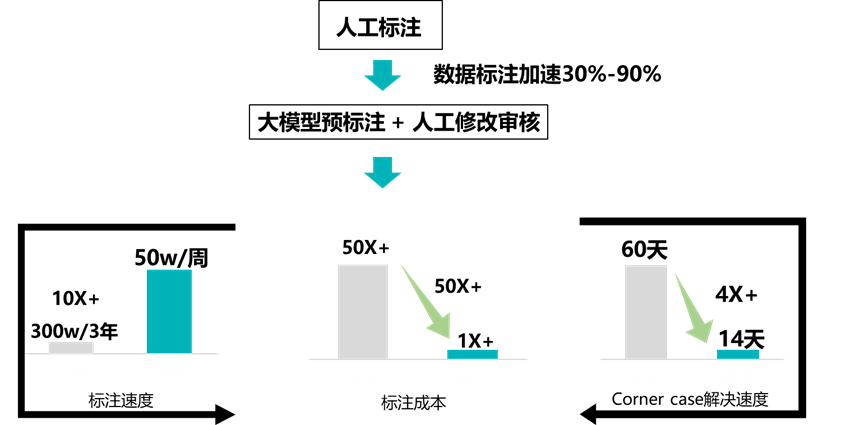
- 实现标注系统降本增效,使标注时间由人工标注的3s/框节省至0.1s/框,标注成本由0.1元/框降至0.02元/框,且可采用本地算力标注的方法,无数据泄露的安全风险。
基于目标位置与关键点的多视角视频生成系统
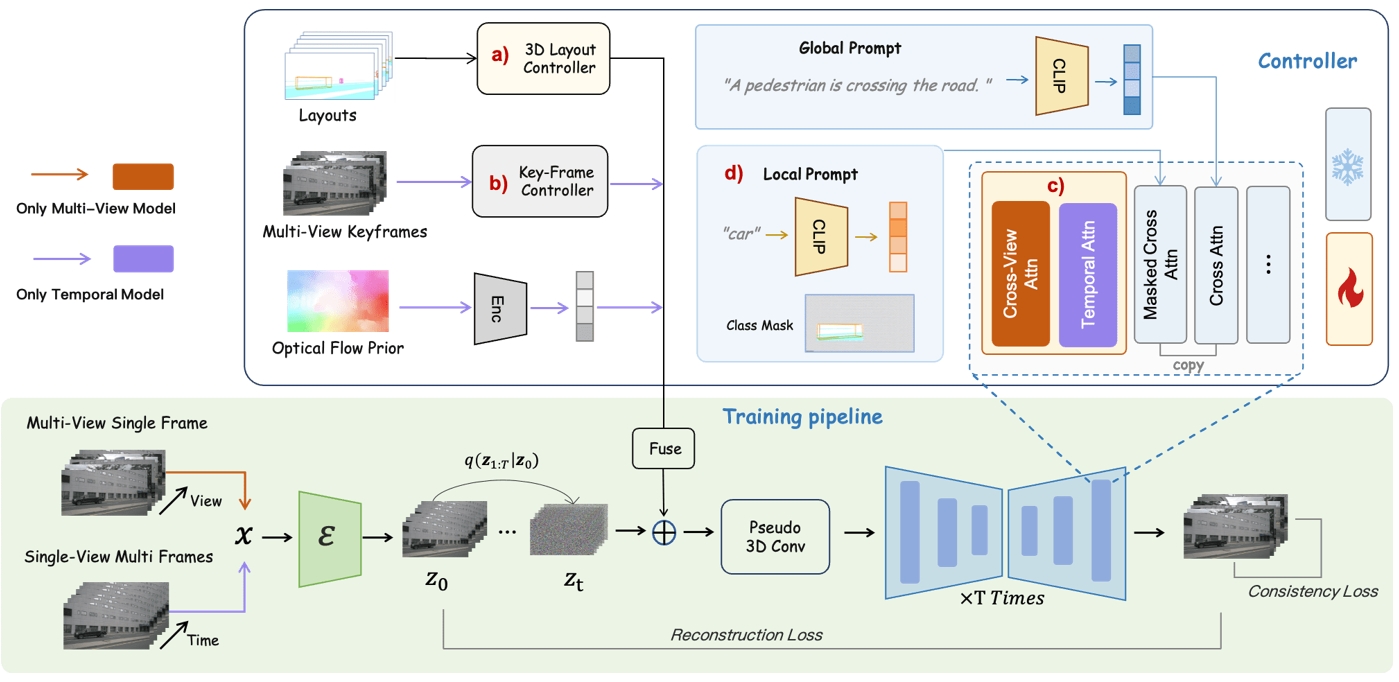
项目亮点: 负责感知大模型训练所需要的Corner Case场景生成,并从0-1搭建视频生成环境、框架以及应用优化迭代流程,并定期与北大、智源、智谱等顶尖研究机构开展市场调研、行业分析与工程落地交流工作。
https://github.com/user-attachments/assets/211ee32b-61e8-46a5-bf9e-fdb5dc069b24
作为视频生成模型,该模型能够根据单帧图像预测未来场景视频,并根据语言提示影响场景中目标运动轨迹的能力。本项目创新性地提出了多个模块,包括:
- layout(2D-3D),即2D-3D的标注框即标签,可以显示目标物体的在3D场景中的相对位置。起到限定目标物类型、位姿、尺寸约束的作用。
- global text prompt,即全局文本提示,可以影响整个视频的生成
- local text prompt,即局部文本提示,可以影响局部目标物的生成
- camera pose,即相机位姿,可以决定单张图片的视角、视场范围
- BEV roadmap,即BEV道路图,可以决定场景整体布局
- optical Flow,即光流(相邻帧光线变化情况),可以决定相邻帧的关联关系,保证局部一致性
- temporal attention,即时间注意力机制,通过学习不同帧之间的通道权重,训练出合理的目标帧间变化趋势
主要成果:
- 通过LoRA微调Unet网络,创新性地提出多个视频生成组件
- 微调出的时序视频生成模型,可以生成具有真实渲染、真实动作、真实轨迹的场景视频,如下图所示:

视频生成模型评估系统
项目亮点:
- 搭建视频生成模型全生命周期流程,确保视频生成质量符合交付要求,并保持模型持续迭代。
- 设计生成视频评价指标,以可具体量化与标准化方法对具体视频生成指标进行测评。
- 设计模型评估Benchmark、自动化评估工具与可视化平台、模型泛化迭代平台、模型管理与运行性能监控平台,并形成集成对接流程交付物,包含Demo工程(测试用例)、集成对接Guidance等
主要成果:
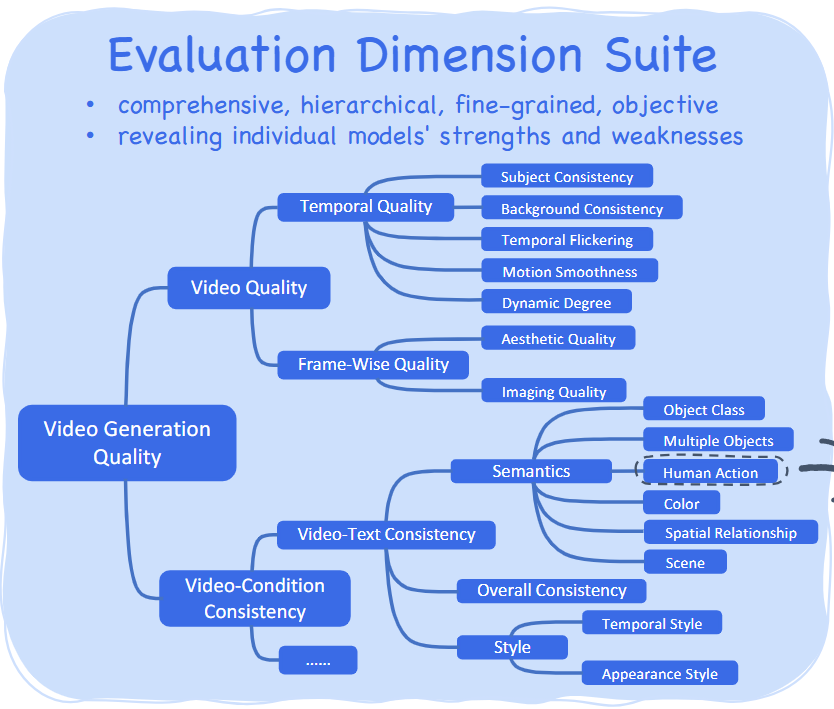
收集了不少于40T的视频数据,并使用视频生成模型评估其质量,总结出的benchmark如下所示:
- 视频质量
- 时间质量(主题一致性、背景一致性、时序闪烁、运动平滑性、动态度)
- 帧相关质量(美学质量、图像质量)
- 视频条件一致性(视频-文本一致性)
- 语义一致性(目标类别、多目标一致性、颜色、空间关联性、场景)
- 风格一致性(时序风格、表现风格)
端云协同的多模态数据飞轮系统
项目亮点:
负责多模态感知数据(如视频、点云、语音及其他结构化数据)融合,基于transformer框架设计了多模态端云协作式感知融合算法,负责算法飞轮系统模型迭代与数据自动化标注 超过50万对图片-文本-点云-标注框数据字典,整体数据量超30T,并设计了五阶段联合训练方法:
- 第一阶段:对齐图像和文本向量
首先,我们使用带描述的图像数据来对齐图像和文本向量,辅助文本对来进行协同训练。这种训练方法使两模态互相促进,提升短文本的检索能力,同时保持跨模态检索性能 - 第二阶段:利用合成数据进行长文本优化 接着,我们引入了由 AI 模型生成的合成数据,主要是长文本图像描述数据,通过增加文本序列长度(至 512)来训练模型。这一阶段重点提升了模型对于长文本的关注和处理能力,进一步优化了文本检索的性能。
- 第三阶段:难负样本学习 在最后阶段,我们使用包含难负样本的文本三元组,进一步改进文本编码器,学习区分相关文本与不相关文本。同时,为保持文本-图像对齐,我们继续对长图像标题进行训练。此阶段显著提升了纯文本性能,模型的图像-文本的跨模态检索能力则保持稳定。
- 第四阶段:引入跨视野注意力机制。此阶段进一步优化了图像-文本对齐的能力,并进一步优化了图像-文本的检索性能。
- 第五阶段:引入时序注意力机制,增强模型对于目标未来运动轨迹的预测。
用户数据(从用户反馈数据获取,同时考虑反馈缺省情况,即用户不反馈表示用户打中等偏上的分数(当然要根据实际情况更新),根据用户prompt序列) -> 更好的模型质量(微调出更好的模型) -> 更好的产品,从而进入模型迭代的正向循环
eg:平台上的数据内容越多,就越能吸引更多的用户,而更多的用户又能以某些方式导致更多的内容出现在平台上。这个过程不需要平台做非常困难的数据挖掘或者持续的智能化升级,以下把这种数据飞轮称为“低垂的数据飞轮“
端侧模型优化部署方案
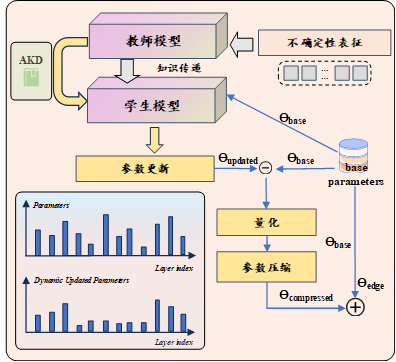
项目亮点:
针对业务中不同任务对量化的要求不同,有些任务需要在压缩比、延迟、资源消耗等指标之间实施精细的平衡系统应提供“开关式”调整工具,包括但不限于:
- 调整激活值统计方案(hist、maxmin、kl、mse、kl-sym等)
- 调整模型权重(adaround、brecq、qdrop)
- 以及其他可以有效提升模型精度的算法或者策略。
与量化工具类似,业务中存在剪枝要求不同的任务,有些任务需要在压缩比、延迟、资源消耗等指标之间实施精细的平衡,这类任务要求剪枝工具能提供灵活的配置手段,同时也有些任务使用默认的策略、配置进行剪枝即可满足产品需求。
- 支持目前通用检测框架(transformer,resnet等骨干网络)的自动化剪枝
- 提供稀疏化训练脚本
- 提供模型权重和模型配置文件导入窗口
- 提供精调训练脚本和精调数据集导入窗口
项目成果:
利用XGBoost小模型学习深度强化学习大模型知识,最终将模型限制在40KB内,模型体积降低98%,使其能够在移动端顺利部署,并加快了模型推理速度
平台规则检索校验RAG模型
项目亮点:
- 法律知识库与其他类型知识库不同,法律知识库需要具备完整且精确的文字表述与逻辑框架。因此,直接使用大语言模型对法律问题进行生成时,会出现偶发的措辞不准确以及幻觉现象,造成回答出现歧义现象,因此,我们采用检索的方法,能够使得回答精确到每一个有效法律条例中。
- 采用向量压缩技术,它能够在保持向量间距离近似不变的前提下,大幅度减少存储和计算成本。
- 使用BGE系列模型,bge-large-zh是一个针对中文文本的预训练模型,其核心功能是将文本转换为高维向量表示。这些向量捕捉了文本中的语义信息,使得语义上相似的文本在向量空间中的距离更近。这种表示方法为后续的相似性搜索和聚类提供了便利。
项目成果:
- 通过将向量空间划分为多个子空间(称为“桶”或“聚类”),使得搜索可以在更小的范围内进行,从而加速搜索过程。
- 使用BM25进行检索,兼顾了算法的实时性需求,减少了客户等待时间
- 使用对比学习的方法,增强了模型的在同类问题上判断准确性与答案分割精度,能够输出更加可靠有效的答案
- 生成多种可供参考的答案,并将最适合于客户的放在首位,从而提升回答选择的多样性
- 利用排序模型进一步过滤候选集,并最终获得精细的文档集,以支持下游大语言模型完成检索增强任务
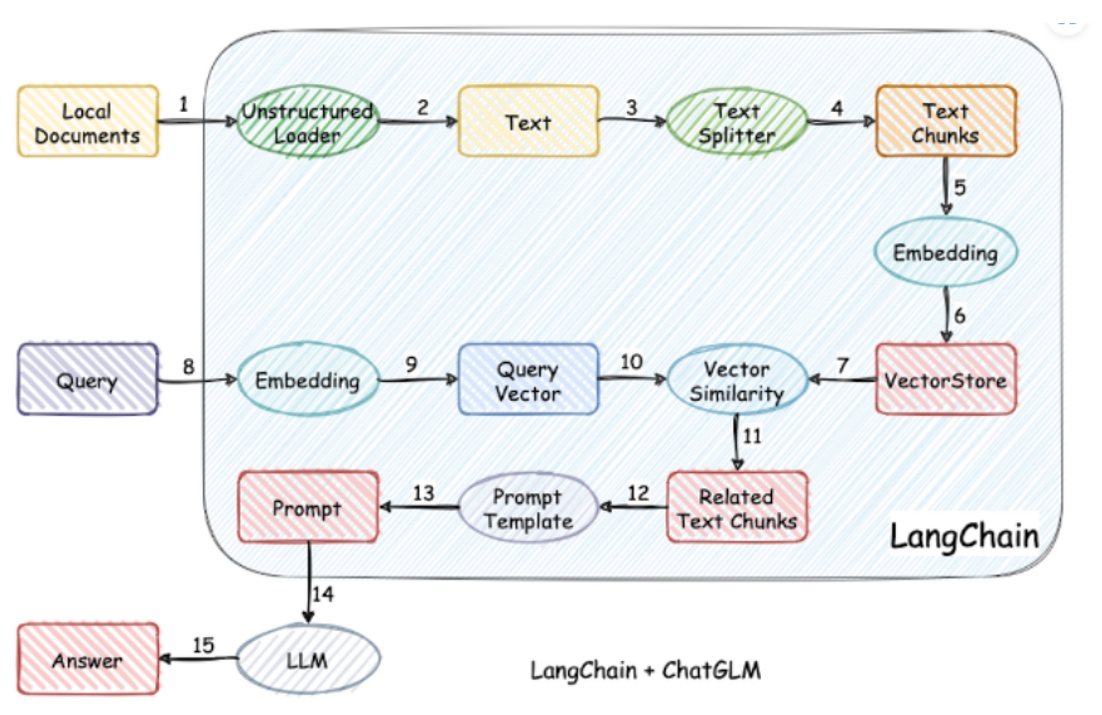
无字幕视频多语识别与字幕生成系统(个人项目)
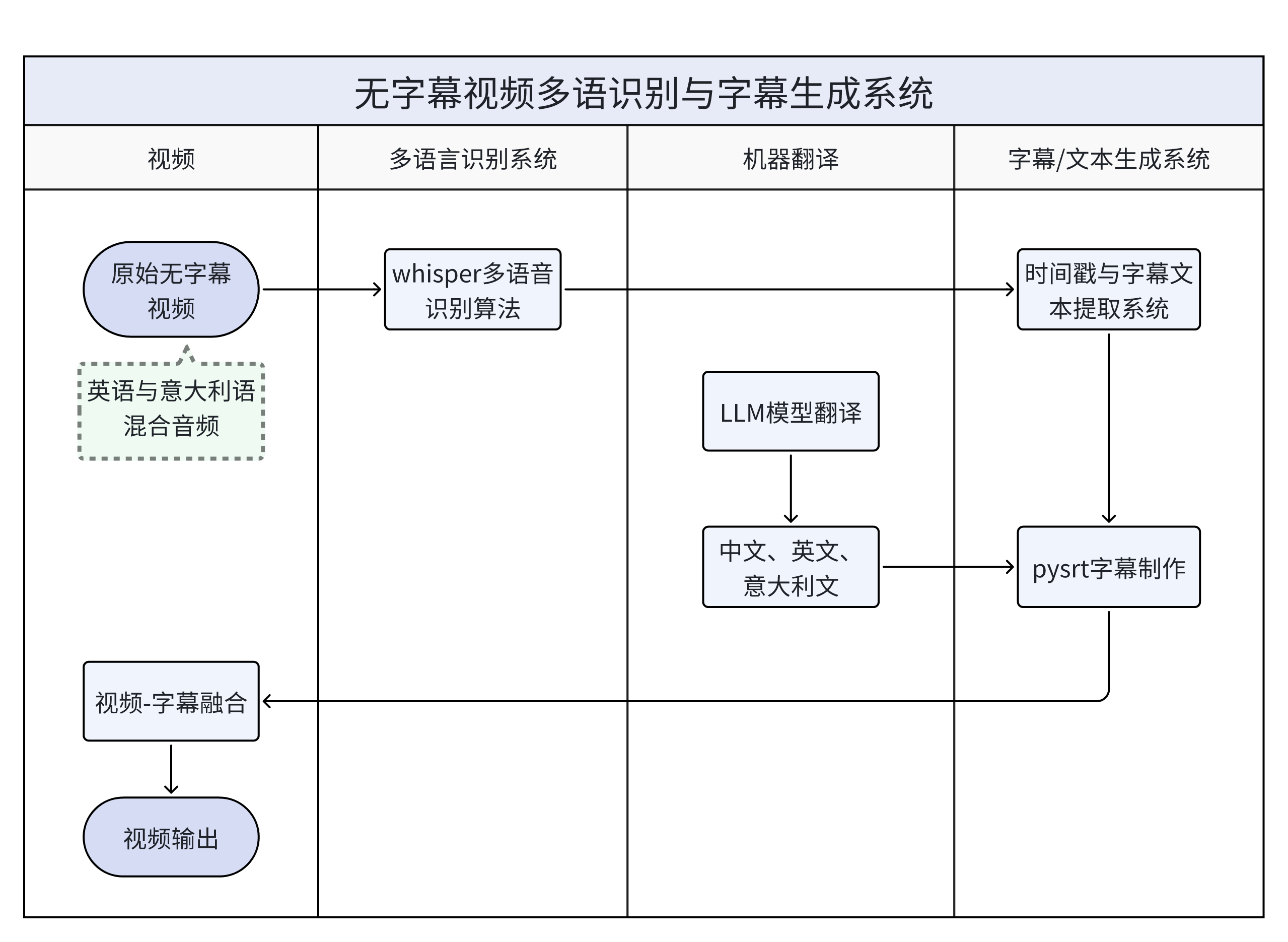
转换前的原视频(节选自GPT-4o官方发布会)为英文与意大利文混合视频,且无字幕,该项目通过Whisper模型提取出时间戳以及对应的英文txt后, 使用LLM模型将英文转化为中文、意大利文,而后使用pysrt生成字幕文件、最后使用moviepy、ffmpeg等工具 将字幕嵌入到视频中,最终形成三语字幕视频。
具体案例可见(原视频也在该账号中):无字幕视频多语识别与字幕生成
技术产品思维之TPF&PMF
- TPF(Technology Product Fit,技术产品匹配),即技术擅长什么,不擅长什么,怎么去做匹配,
- PMF(Product Market Fit,产品市场匹配),即在一个好的市场里, 能够用一个产品去满足这个市场。
杨植麟和王小川都在不同场合表达了这一理念的重要性:
- 技术范式发生了很大的改变。首先是前端变成了对话式的 Conversation UI,未来可能会有越来越多的产品采用这种 UI,后端也被极大程度的统一了,统一到了一个「语言模型」上。这个模型处理的不光是语言,它能处理世界上所有的信息,本质上是对世界上所有信息进行编码和无损压缩。
但TPF和PMF并不是二选一的关系
需求来源于市场,产品经理在接触到需求后,会结合对大模型的理解,协调出技术实现方案,包括寻找到测试集给到技术,并协同寻找数据集,包括其他的手段一起来定义产品。 接着呢,还是要把产品丢到市场上,不断的迭代,来从MVP迈到PMF,并开始放量增长。
所以,在大模型时代:TPF是为了内部落地正确的做事,PMF是最终对用户做正确的事
For more info
For more information, please contact me at gongwenzhi98@foxmail.com